top pages
Soapbox
Company
| Blocked view design details Blocked views make it possible to maintain views with large numbers of rows without using very large columns (which take more time to load, are much less efficient to change, and tend to make bad use of free space, especially when growing bit by bit). The idea is to carve one long logical view up into many smaller subviews:
Some comments about this structure:
what about columns? The one thing to keep in mind in the above structure, is that everything continues to be column-oriented. In other words, each block / subview is still a set of (smaller) columns. So a view containing 1,000,000 rows with an int and a string property will end up as approximately 1,000 subviews, each having an int and a string column, each in turn containing around 1,000 values. When compared to B-trees, there are a number of differences:
One might think that this simpler design is not nearly as scalable and balanced as real B-trees, but results so far indicate that scalability of blocked views is surprisingly good. One explanation for this could be that O(log N) performance instead of O(N) does kick in: a single access to the last subview is sufficient to avoid accesses to all but one other subview, i.e. at most two subviews need to be accessed. Metakit 2.4.9.2 does not yet make optimal use of blocked views when searching in sorted content. The binary search needs to be restricted to locate the subview by first searching only in the last view - right now it just does the usual bisection, hitting more subviews than strictly needed. Another missing optimization is to cache the location of the last access, which would significantly reduce the work needed when iterating over the entire view - a common operation. Again, bisection is used to locate the subview (but without accessing the storage in this case, so it's not really that bad). | metakit index • Overview • Quotes • Links | |||
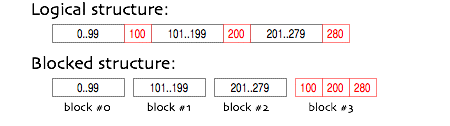 The special trick, is that one row between each of the blocks is taken out and collected into a separate block at the end.
The special trick, is that one row between each of the blocks is taken out and collected into a separate block at the end.